I've been really enjoying Deno for personal projects! The developer experience is excellent and Deno Deploy makes it easy to quickly & easily get things deployed.
While its on-demand design is efficient and excellent for many use cases, there are some where it performs poorly due to its nature of creating a new instance for each request. Unfortunately, I ran into one of these when building a caching layer for a project I've been working on. In this article I'll go through these issues and explain the alternative route I went to avoid them.
The problem: Redis overload 👯👯👯
Database reads are expensive and slow. There's a multitude of other reasons why caching is essential, but for the project I'm working on I'm using supabase and their free tier supports only a limited amount of bandwidth. To avoid any rate-limiting I added a Redis layer in front of it to reduce the number of queries that hit the database directly.
Conveniently, Deno has a deno-redis (experimental) plugin which I used to add a simple caching layer to my project:
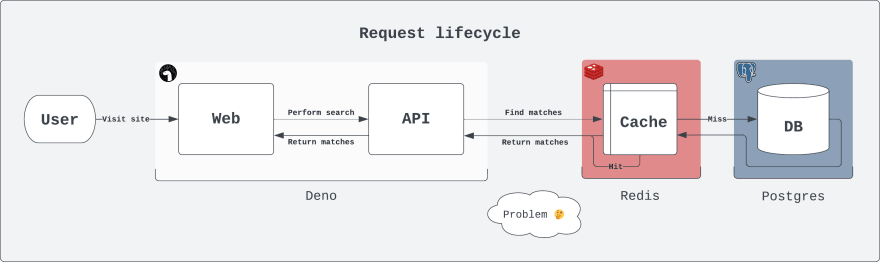
With this in place, the full request lifecycle looks like this:
And this works just fine! But, after enough requests start pouring in Redis will complain that there are too many connections and not allow new ones (redis.connect results in: ERR max number of clients reached). Granted, I am also using their free tier which restricts to 30 clients at a time. But this problem will also arise in high-volume applications as hosted integrations generally have a hard cap on the number of connections.
Why does this happen? It's due to a fundamental aspect of Deno Deploy: each time a request is made a completely new context is created and in this scenario, a new connection to Redis must be made. To visualize this, here is what happens when n users each make a request:
To get around this we'll need a way to cut down on the number of connections and keep it under the limit, but as we'll see there's also a performance benefit to doing this.
A single, persistent connection 🛰️
Though any traditional server environment will enable this, I used Node as it's close to Deno and simple to use. With a few lines of code, an express server that creates a single client on start will enable any incoming request to reuse the same connection. Adding some simple routing to detect request params and respond with what Redis returns then lets allows the cache requests in Deno to be swapped with GET requests to this server.
This is known as a reverse proxy and is common in any web stack. With this in place, the request lifecycle now looks like this:
With this in place, not only are there no errors due to the number of connections but performance is significantly improved with duration cut by over 50%:
benchmark
time (avg)
(min … max)
p75
p99
Deno -> Redis
65.06 ms/iter
(792 ns … 114.68 ms)
111.41 ms
114.68 ms
Deno -> Node -> Redis
34.79 ms/iter
(28.4 ms … 41.7 ms)
36.53 ms
41.7 m
But there's a twist! 🦹♂️
My main objective was to identify a solution for the Redis errors, but I figured why not also test whether a persistent Postgres connection behaves similarly. And to my surprise, the results were the opposite!
Perplexingly, when benchmarking the same as above (Deno vs Deno + Node layer for Postgres) there was a surprising result: Deno outperformed Node by a factor of ~2x! So despite recreating a supabase client for each request, Deno still outperforms Node:
benchmark
time (avg)
(min … max)
p75
p99
Deno -> Postgres
42.98 ms/iter
(916 ns … 89.29 ms)
79.8 ms
89.29 ms
Deno -> Node -> Postgres
88.24 ms/iter
(667 ns … 205.44 ms)
160.8 ms
205.44 ms
Whether this is due to limitations in the implementation of @supabase/supabase-js that aren't present in Deno's or just that Deno performs better I am not completely sure. And as far as I'm aware there isn't a limitation on the number of clients connecting to a single supabase instance. But based on these numbers I'll keep Node for querying Redis and Deno for querying Postgres.
Thanks for reading!
Here's the source used to run each of these benchmarks if you'd like to try them yourself: